由于Kubernetes已经release了1.15版本,此文档不再维护!
更新记录
- 2019年2月13日由于runc逃逸漏洞CVE-2019-5736,根据kubernetes的文档建议,修改docker-ce版本为18.09.2
- 2019年1月7日添加基于ingress-nginx使用域名+HTTPS的方式访问kubernetes-Dashboard
- 2019年1月2日添加RBAC规则,修复kube-apiserver无法访问kubelet的问题
- 2019年1月1日调整master节点和worker节点的操作步骤,添加CoreDNS的configmap中的hosts静态解析
- 2018年12月28日修改kube-prometheus部分,修复Prometheus的Targets无法发现的问题
- 2018年12月26日修改kubernetes-dashboard链接指向
- 2018年12月25日修改kubele.config.file路径问题
- 2018年12月18日修改kubelet和kube-proxy启动时加载config file
- 2018年12月17日添加EFK部署内容
- 2018年12月16日添加prometheus-operator部署内容
- 2018年12月14日添加helm部署内容,拆分etcd的server证书和client证书
- 2018年12月13日添加rook-ceph部署内容
- 2018年12月12日添加Metrics-Server内容
- 2018年12月11日添加Dashboard、Ingress内容
- 2018年12月10日添加kube-flannel、calico、CoreDNS内容
- 2018年12月9日分拆master节点和work节点的内容
- 2018年12月8日初稿
介绍
本次部署方式为二进制可执行文件的方式部署
- 注意请根据自己的实际情况调整
- 对于生产环境部署,请注意某些参数的选择
如无特殊说明,均在k8s-m1节点上执行
参考博文
感谢两位大佬的文章,这里整合一下两位大佬的内容,结合自己的理解整理本文
软件版本
- kubernetes v1.11.5 【下载链接需要爬墙,自行解决】
- docker-ce 18.03
- cni-plugin v0.7.4
- etcd v3.3.10
网络信息
- 基于CNI的模式实现容器网络
- Cluster IP CIDR:
10.244.0.0/16- Service Cluster IP CIDR:
10.96.0.0/12- Service DNS IP:
10.96.0.10- Kubernetes API VIP:
172.16.80.200
节点信息
- 操作系统可采用
Ubuntu Server 16.04+和CentOS 7.4+,本文使用CentOS 7.6 (1810) Minimal- 由
keepalived提供VIP- 由
haproxy提供kube-apiserver四层负载均衡- 由于实验环境受限,以3台服务器同时作为master和worker节点运行
- 服务器配置请根据实际情况适当调整
| IP地址 | 主机名 | 角色 | CPU | 内存 |
|---|---|---|---|---|
| 172.16.80.201 | k8s-m1 | master+worker | 4 | 8G |
| 172.16.80.202 | k8s-m2 | master+worker | 4 | 8G |
| 172.16.80.203 | k8s-m3 | master+worker | 4 | 8G |
目录说明
- /usr/local/bin/:存放kubernetes和etcd二进制文件
- /opt/cni/bin/: 存放cni-plugin二进制文件
- /etc/etcd/:存放etcd配置文件和SSL证书
- /etc/kubernetes/:存放kubernetes配置和SSL证书
- /etc/cni/net.d/:安装CNI插件后会在这里生成配置文件
- $HOME/.kube/:kubectl命令会在家目录下建立此目录,用于保存访问kubernetes集群的配置和缓存
- $HOME/.helm/:helm命令会建立此目录,用于保存helm缓存和repository信息
事前准备
事情准备在所有服务器上都需要完成
部署过程以
root用户完成
- 所有服务器
网络互通,k8s-m1可以通过SSH证书免密登录到其他master节点,用于分发文件 - 编辑
/etc/hosts
1 | cat > /etc/hosts <<EOF |
- 时间同步服务
集群系统需要各节点时间同步
参考链接:RHEL7官方文档
这里使用公网对时,如果需要内网对时,请自行配置
1 | yum install -y chrony |
- 关闭firewalld和SELINUX(可根据实际情况自行决定关闭不需要的服务)
1 | systemctl stop firewalld |
1 | setenforce 0 |
- 禁用swap
1 | swapoff -a && sysctl -w vm.swappiness=0 |
- 添加
sysctl参数
1 | cat > /etc/sysctl.d/centos.conf <<EOF |
- 确保操作系统已经最新
1 | yum update -y |
- 安装软件包
1 | yum groups install base -y |
- 加载ipvs模块
1 | 开机自动加载ipvs模块 |
- 安装docker-ce 18.09.2
1 | yum remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate docker-selinux docker-engine-selinux docker-engine -y |
- 创建docker配置文件
1 | mkdir -p /etc/docker |
- 配置docker命令补全
1 | cp /usr/share/bash-completion/completions/docker /etc/bash_completion.d/ |
- 配置docker服务开机自启动
1 | systemctl enable docker.service |
- 查看docker信息
1 | docker info |
- 禁用docker源
1 | 为避免yum update时更新docker,将docker源禁用 |
- 确保以最新的内核启动系统
1 | reboot |
定义集群变量
注意
- 这里的变量只对当前会话生效,如果会话断开或者重启服务器,都需要重新定义变量
HostArray定义集群中所有节点的主机名和IPMasterArray定义master节点的主机名和IPWorkerArray定义worker节点的主机名和IP,这里master和worker都在一起,所以MasterArray和WorkerArray一样VIP_IFACE定义keepalived的VIP绑定在哪一个网卡ETCD_SERVERS以MasterArray的信息生成etcd集群服务器列表ETCD_INITIAL_CLUSTER以MasterArray信息生成etcd集群初始化列表POD_DNS_SERVER_IP定义Pod的DNS服务器IP地址
1 | declare -A HostArray MasterArray WorkerArray |
下载所需软件包
- 创建工作目录
1 | mkdir -p /root/software |
- 二进制文件需要分发到master和worker节点
1 | 下载kubernetes二进制包 |
生成集群Key和Certificates
说明
本次部署,需要为etcd-server、etcd-client、kube-apiserver、kube-controller-manager、kube-scheduler、kube-proxy生成证书。另外还需要生成sa、front-proxy-ca、front-proxy-client证书用于集群的其他功能。
- 要注意CA JSON文件的
CN(Common Name)与O(Organization)等内容是会影响Kubernetes组件认证的。
CNCommon Name,kube-apiserver会从证书中提取该字段作为请求的用户名(User Name)OOragnization,kube-apiserver会从证书中提取该字段作为请求用户的所属组(Group)- CA是自签名根证书,用来给后续各种证书签名
- kubernetes集群的所有状态信息都保存在etcd中,kubernetes组件会通过kube-apiserver读写etcd里面的信息
- etcd如果暴露在公网且没做SSL/TLS验证,那么任何人都能读写数据,那么很可能会无端端在kubernetes集群里面多了挖坑Pod或者肉鸡Pod
- 本文使用
CFSSL创建证书,证书有效期10年- 建立证书过程在k8s-m1上完成
下载CFSSL工具
1 | wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -O /usr/local/bin/cfssl-certinfo |
创建工作目录
1 | mkdir -p /root/pki /root/master /root/worker |
创建用于生成证书的json文件
ca-config.json
1 | cat > ca-config.json <<EOF |
ca-csr.json
1 | cat > ca-csr.json <<EOF |
etcd-ca-csr.json
1 | cat > etcd-ca-csr.json <<EOF |
etcd-server-csr.json
1 | cat > etcd-server-csr.json <<EOF |
etcd-client-csr.json
1 | cat > etcd-client-csr.json <<EOF |
kube-apiserver-csr.json
1 | cat > kube-apiserver-csr.json <<EOF |
kube-manager-csr.json
1 | cat > kube-manager-csr.json <<EOF |
kube-scheduler-csr.json
1 | cat > kube-scheduler-csr.json <<EOF |
kube-proxy-csr.json
1 | cat > kube-proxy-csr.json <<EOF |
kube-admin-csr.json
1 | cat > kube-admin-csr.json <<EOF |
front-proxy-ca-csr.json
1 | cat > front-proxy-ca-csr.json <<EOF |
front-proxy-client-csr.json
1 | cat > front-proxy-client-csr.json <<EOF |
sa-csr.json
1 | cat > sa-csr.json <<EOF |
创建etcd证书
etcd-ca证书
1 | echo '--- 创建etcd-ca证书 ---' |
etcd-server证书
1 | echo '--- 创建etcd-server证书 ---' |
etcd-client证书
1 | echo '--- 创建etcd-client证书 ---' |
创建kubernetes证书
kubernetes-CA 证书
1 | echo '--- 创建kubernetes-ca证书 ---' |
kube-apiserver证书
1 | echo '--- 创建kube-apiserver证书 ---' |
kube-controller-manager证书
1 | echo '--- 创建kube-controller-manager证书 ---' |
kube-scheduler证书
1 | echo '--- 创建kube-scheduler证书 ---' |
kube-proxy证书
1 | echo '--- 创建kube-proxy证书 ---' |
kube-admin证书
1 | echo '--- 创建kube-admin证书 ---' |
Front Proxy证书
1 | echo '--- 创建Front Proxy Certificate证书 ---' |
Service Account证书
1 | echo '--- 创建service account证书 ---' |
bootstrap-token
1 | BOOTSTRAP_TOKEN=$(dd if=/dev/urandom bs=128 count=1 2>/dev/null | base64 | tr -d "=+/[:space:]" | dd bs=32 count=1 2>/dev/null) |
encryption.yaml
1 | ENCRYPTION_TOKEN=$(head -c 32 /dev/urandom | base64) |
audit-policy.yaml
1 | echo '--- 创建创建高级审计配置 ---' |
创建kubeconfig文件
说明
- kubeconfig 文件用于组织关于集群、用户、命名空间和认证机制的信息。
- 命令行工具
kubectl从 kubeconfig 文件中得到它要选择的集群以及跟集群 API server 交互的信息。- 默认情况下,
kubectl会从$HOME/.kube目录下查找文件名为config的文件。
注意: 用于配置集群访问信息的文件叫作
kubeconfig文件,这是一种引用配置文件的通用方式,并不是说它的文件名就是kubeconfig。
kube-controller-manager.kubeconfig
1 | echo "Create kube-controller-manager kubeconfig..." |
kube-scheduler.kubeconfig
1 | echo "Create kube-scheduler kubeconfig..." |
kube-proxy.kubeconfig
1 | echo "Create kube-proxy kubeconfig..." |
kube-admin.kubeconfig
1 | echo "Create kube-admin kubeconfig..." |
bootstrap.kubeconfig
1 | echo "Create kubelet bootstrapping kubeconfig..." |
清理证书CSR文件
1 | echo '--- 删除*.csr文件 ---' |
修改文件权限
1 | chown root:root *pem *kubeconfig *yaml *csv |
检查生成的文件
1 | ls -l | grep -v json |
kubernetes-master节点
本节介绍如何部署kubernetes master节点
master节点说明
- 原则上,master节点不应该运行业务Pod,且不应该暴露到公网环境!!
- 边界节点,应该交由
worker节点或者运行Ingress的节点来承担- 以
kubeadm部署为例,部署完成后,会给master节点添加node-role.kubernetes.io/master=''标签(Labels)并且会对带有此标签的节点添加node-role.kubernetes.io/master:NoSchedule污点(taints),这样不能容忍此污点的Pod无法调度到master节点- 本文中,在kubelet启动参数里,默认添加
node-role.kubernetes.io/node=''标签(Labels),且没有对master节点添加node-role.kubernetes.io/master:NoSchedule污点(taints)- 生产环境中最好参照kubeadm,对master节点添加
node-role.kubernetes.io/master=''标签(Labels)和node-role.kubernetes.io/master:NoSchedule污点(taints)
kube-apiserver
- 以 REST APIs 提供 Kubernetes 资源的 CRUD,如授权、认证、存取控制与 API 注册等机制。
- 关闭默认非安全端口8080,在安全端口 6443 接收 https 请求
- 严格的认证和授权策略 (x509、token、RBAC)
- 开启 bootstrap token 认证,支持 kubelet TLS bootstrapping
- 使用 https 访问 kubelet、etcd,加密通信
kube-controller-manager
- 通过核心控制循环(Core Control Loop)监听 Kubernetes API
的资源来维护集群的状态,这些资源会被不同的控制器所管理,如 Replication Controller、Namespace
Controller 等等。而这些控制器会处理着自动扩展、滚动更新等等功能。- 关闭非安全端口,在安全端口 10252 接收 https 请求
- 使用 kubeconfig 访问 kube-apiserver 的安全端口
kube-scheduler
- 负责将一个(或多个)容器依据调度策略分配到对应节点上让容器引擎(如 Docker)执行。
- 调度受到 QoS 要求、软硬性约束、亲和性(Affinity)等等因素影响。
HAProxy
- 提供多个 API Server 的负载均衡(Load Balance)
- 监听VIP的
8443端口负载均衡到三台master节点的6443端口
Keepalived
- 提供虚拟IP位址(VIP),来让vip落在可用的master主机上供所有组件访问master节点
- 提供健康检查脚本用于切换VIP
添加用户
- 这里强迫症发作,指定了
UID和GID- 不指定
UID和GID也可以
1 | echo '--- master节点添加用户 ---' |
创建目录
1 | echo '--- master节点创建目录 ---' |
分发证书文件和kubeconfig到master节点
1 | for NODE in "${!MasterArray[@]}";do |
分发二进制文件
- 在k8s-m1上操作
1 | echo '--- 分发kubernetes和etcd二进制文件 ---' |
部署配置Keepalived和HAProxy
- 在k8s-m1上操作
切换工作目录
1 | cd /root/master |
安装Keepalived和HAProxy
1 | for NODE in "${!MasterArray[@]}";do |
配置keepalived
- 编辑
keepalived.conf模板- 替换
keepalived.conf的字符串- 编辑
check_haproxy.sh
1 | cat > keepalived.conf.example <<EOF |
1 | cat > check_haproxy.sh <<EOF |
配置haproxy
- 编辑
haproxy.cfg模板
1 | cat > haproxy.cfg.example <<EOF |
分发配置文件到master节点
1 | for NODE in "${!MasterArray[@]}";do |
启动keepalived和haproxy
1 | for NODE in "${!MasterArray[@]}";do |
验证VIP
- 需要大约十秒的时间等待keepalived和haproxy服务起来
- 这里由于后端的kube-apiserver服务还没启动,只测试是否能ping通VIP
- 如果VIP没起来,就要去确认一下各master节点的keepalived服务是否正常
1 | sleep 15 |
部署etcd集群
- 每个etcd节点的配置都需要做对应更改
- 在k8s-m1上操作
配置etcd.service文件
1 | cat > etcd.service <<EOF |
etcd.config.yaml模板
- 关于各个参数的说明可以看这里
1 | cat > etcd.config.yaml.example <<EOF |
分发配置文件
1 | 根据节点信息替换文本,分发到各etcd节点 |
启动etcd集群
- etcd 进程首次启动时会等待其它节点的 etcd 加入集群,命令 systemctl start etcd 会卡住一段时间,为正常现象
- 启动之后可以通过
etcdctl命令查看集群状态
1 | for NODE in "${!MasterArray[@]}";do |
- 为方便维护,可使用alias简化etcdctl命令
1 | cat >> /root/.bashrc <<EOF |
验证etcd集群状态
- etcd提供v2和v3两套API,kubernetes使用v3
1 | 应用上面定义的alias |
Master组件服务
master组件配置模板
kube-apiserver.conf
--allow-privileged=true启用容器特权模式
--apiserver-count=3指定集群运行模式,其它节点处于阻塞状态
--audit-policy-file=/etc/kubernetes/audit-policy.yaml基于audit-policy.yaml文件定义的内容启动审计功能
--authorization-mode=Node,RBAC开启 Node 和 RBAC 授权模式,拒绝未授权的请求
--disable-admission-plugins=和--enable-admission-plugins禁用和启用准入控制插件。准入控制插件会在请求通过认证和授权之后、对象被持久化之前拦截到达apiserver的请求。
准入控制插件依次执行,因此需要注意顺序。
如果插件序列中任何一个拒绝了请求,则整个请求将立刻被拒绝并返回错误给客户端。
关于admission-plugins官方文档里面有推荐配置,这里直接采用官方配置,注意针对不同kubernetes版本都会有不一样的配置,具体可以看这里
--enable-bootstrap-token-auth=true启用 kubelet bootstrap 的 token 认证--experimental-encryption-provider-config=/etc/kubernetes/encryption.yaml启用加密特性将Secret数据加密存储到etcd--insecure-port=0关闭监听非安全端口8080--runtime-config=api/all=true启用所有版本的 APIs--service-cluster-ip-range=10.96.0.0/12指定 Service Cluster IP 地址段--service-node-port-range=30000-32767指定 NodePort 的端口范围--token-auth-file=/etc/kubernetes/token.csv保存bootstrap的token信息--target-ram-mb配置缓存大小,参考值为节点数*60
1 | cat > kube-apiserver.conf.example <<EOF |
kube-controller-manager.conf
--allocate-node-cidrs=true在cloud provider上分配和设置pod的CIDR--cluster-cidr集群内的pod的CIDR范围,需要--allocate-node-cidrs设为true--experimental-cluster-signing-duration=8670h0m0s指定 TLS Bootstrap 证书的有效期--feature-gates=RotateKubeletServerCertificate=true开启 kublet server 证书的自动更新特性--horizontal-pod-autoscaler-use-rest-clients=true能够使用自定义资源(Custom Metrics)进行自动水平扩展--leader-elect=true集群运行模式,启用选举功能,被选为 leader 的节点负责处理工作,其它节点为阻塞状态--node-cidr-mask-size=24集群中node cidr的掩码--service-cluster-ip-range=10.96.0.0/16指定 Service Cluster IP 网段,必须和 kube-apiserver 中的同名参数一致--terminated-pod-gc-thresholdexit状态的pod超过多少会触发gc
1 | cat > kube-controller-manager.conf.example <<EOF |
kube-scheduler.conf
--leader-elect=true集群运行模式,启用选举功能,被选为 leader 的节点负责处理工作,其它节点为阻塞状态
1 | cat > kube-scheduler.conf.example <<EOF |
systemd服务文件
kube-apiserver.service
1 | cat > kube-apiserver.service <<EOF |
kube-controller-manager.service
1 | cat > kube-controller-manager.service <<EOF |
kube-scheduler.service
1 | cat > kube-scheduler.service <<EOF |
分发配置文件到各master节点
- 根据master节点的信息替换配置文件里面的字段
1 | for NODE in "${!MasterArray[@]}";do |
启动kubernetes服务
- 可以先在k8s-m1上面启动服务,确认正常之后再在其他master节点启动
1 | systemctl enable --now kube-apiserver.service |
1 | kubectl --kubeconfig=/etc/kubernetes/kube-admin.kubeconfig get cs |
1 | for NODE in "${!MasterArray[@]}";do |
- 三台master节点的
kube-apiserver、kube-controller-manager、kube-scheduler服务启动成功后可以测试一下
1 | kubectl --kubeconfig=/etc/kubernetes/kube-admin.kubeconfig get endpoints |
设置kubectl
- kubectl命令默认会加载
~/.kube/config文件,如果文件不存在则连接http://127.0.0.1:8080,这显然不符合预期,这里使用之前生成的kube-admin.kubeconfig- 在k8s-m1上操作
1 | for NODE in "${!MasterArray[@]}";do |
设置命令补全
- 设置
kubectl命令自动补全
1 | for NODE in "${!MasterArray[@]}";do |
设置kubelet的bootstrap启动所需的RBAC
当集群开启了 TLS 认证后,每个节点的 kubelet 组件都要使用由 apiserver 使用的 CA 签发的有效证书才能与
apiserver 通讯;此时如果节点多起来,为每个节点单独签署证书将是一件非常繁琐的事情;TLS bootstrapping 功能就是让 kubelet 先使用一个预定的低权限用户连接到 apiserver,然后向 apiserver 申请证书,kubelet 的证书由 apiserver 动态签署;在其中一个master节点上执行就可以,以k8s-m1为例
创建工作目录
1 | mkdir -p /root/yaml/tls-bootstrap |
kubelet-bootstrap-rbac.yaml
1 | 创建yaml文件 |
tls-bootstrap-clusterrole.yaml
1 | 创建yaml文件 |
node-client-auto-approve-csr.yaml
1 | 创建yaml文件 |
node-client-auto-renew-crt.yaml
1 | 创建yaml文件 |
node-server-auto-renew-crt.yaml
1 | 创建yaml文件 |
创建tls-bootstrap-rbac
1 | kubectl apply -f . |
设置kube-apiserver获取node信息的权限
说明
本文部署的kubelet关闭了匿名访问,因此需要额外为kube-apiserver添加权限用于访问kubelet的信息
若没添加此RBAC,则kubectl在执行logs、exec等指令的时候会提示401 Forbidden
1 | kubectl -n kube-system logs calico-node-pc8lq |
参考文档:Kublet的认证授权
创建yaml文件
1 | cat > /root/yaml/apiserver-to-kubelet-rbac.yaml <<EOF |
创建RBAC
1 | kubectl apply -f /root/yaml/apiserver-to-kubelet-rbac.yaml |
kubernetes worker节点
worker节点说明
- 安装Docker-ce,配置与master节点一致即可
- 安装cni-plugins、kubelet、kube-proxy
- 关闭防火墙和SELINUX
- kubelet和kube-proxy运行需要root权限
- 这里是以k8s-m1、k8s-m2、k8s-m3作为Work节点加入集群
kubelet
- 管理容器生命周期、节点状态监控
- 目前 kubelet 支持三种数据源来获取节点Pod信息:
- 本地文件
- 通过 url 从网络上某个地址来获取信息
- API Server:从 kubernetes master 节点获取信息
- 使用kubeconfig与kube-apiserver通信
- 这里启用
TLS-Bootstrap实现kubelet证书动态签署证书,并自动生成kubeconfig
kube-proxy
- Kube-proxy是实现Service的关键插件,kube-proxy会在每台节点上执行,然后监听API Server的Service与Endpoint资源物件的改变,然后来依据变化调用相应的组件来实现网路的转发
- kube-proxy可以使用
userspace(基本已废弃)、iptables(默认方式)和ipvs来实现数据报文的转发- 这里使用的是性能更好、适合大规模使用的
ipvs- 使用kubeconfig与kube-apiserver通信
切换工作目录
- 在k8s-m1上操作
1 | cd /root/worker |
worker组件配置模板
kubelet.conf
--bootstrap-kubeconfig=/etc/kubernetes/bootstrap.kubeconfig指定bootstrap启动时使用的kubeconfig--network-plugin=cni定义网络插件,Pod生命周期使用此网络插件--node-labels=node-role.kubernetes.io/node=''kubelet注册当前Node时设置的Label,以key=value的格式表示,多个labe以逗号分隔--pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.1Pod的pause镜像
1 | cat > kubelet.conf <<EOF |
kubelet.config.file
1 | cat > kubelet.config.file <<EOF |
kube-proxy.conf
1 | cat > kube-proxy.conf <<EOF |
kube-proxy.config.file
1 | cat > kube-proxy.config.file <<EOF |
systemd服务文件
kubelet.service
1 | cat > kubelet.service <<EOF |
kube-proxy.service
1 | cat > kube-proxy.service <<EOF |
分发证书和kubeconfig文件
- 在k8s-m1上操作
- 在worker节点建立对应的目录
1 | for NODE in "${!WorkerArray[@]}";do |
分发二进制文件
- 在k8s-m1上操作
1 | for NODE in "${!WorkerArray[@]}";do |
分发配置文件和服务文件
1 | for NODE in "${!WorkerArray[@]}";do |
启动服务
1 | for NODE in "${!WorkerArray[@]}";do |
获取节点信息
- 此时由于未按照网络插件,所以节点状态为
NotReady
1 | kubectl get node -o wide |
kubernetes Core Addons
网络组件部署(二选其一)
- 只要符合CNI规范的网络组件都可以给kubernetes使用
- 网络组件清单可以在这里看到Network Plugins
- 这里只列举
kube-flannel和calico,flannel和calico的区别可以自己去找资料- 网络组件只能选一个来部署
- 本文使用
kube-flannel部署网络组件,calico已测试可用- 在k8s-m1上操作
创建工作目录
1 | mkdir -p /root/yaml/network-plugin/{kube-flannel,calico} |
kube-flannel
说明
- kube-flannel基于VXLAN的方式创建容器二层网络,使用端口
8472/UDP通信- flannel 第一次启动时,从 etcd 获取 Pod 网段信息,为本节点分配一个未使用的 /24 段地址,然后创建 flannel.1(也可能是其它名称,如 flannel1 等) 接口。
- 官方提供yaml文件部署为
DeamonSet- 若需要使用
NetworkPolicy功能,可以关注这个项目canal
架构图
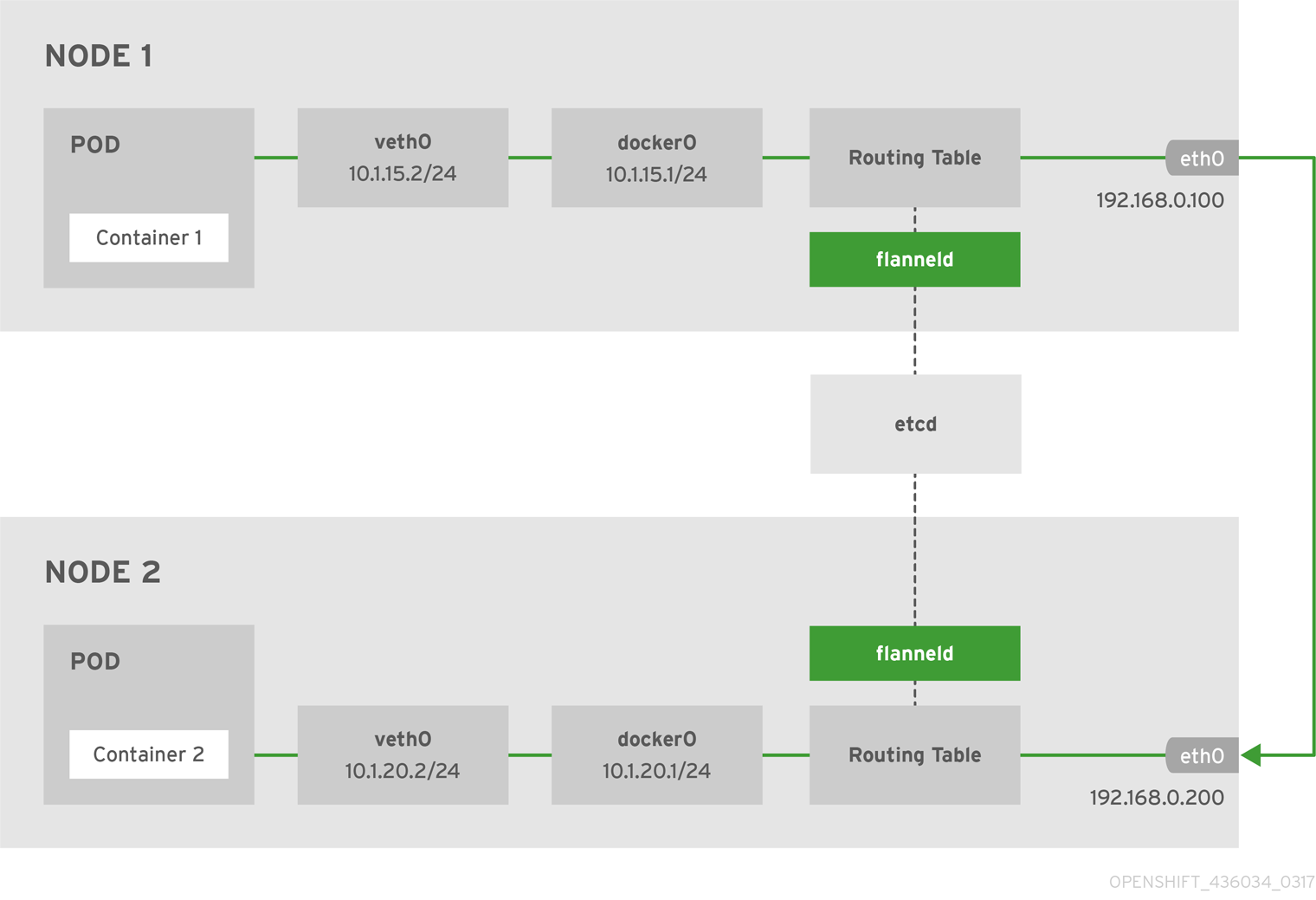
切换工作目录
1 | cd /root/yaml/network-plugin/kube-flannel |
下载yaml文件
1 | wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml |
官方yaml文件包含多个平台的daemonset,包括amd64、arm64、arm、ppc64le、s390x
这里以amd64作为例子,其他的可以自行根据需要修改或者直接删除不需要的daemonset
官方yaml文件已经配置好容器网络为
10.244.0.0/16,这里需要跟kube-controller-manager.conf里面的--cluster-cidr匹配如果在
kube-controller-manager.conf里面把--cluster-cidr改成了其他地址段,例如192.168.0.0/16,用以下命令替换kube-flannel.yaml相应的字段
1 | sed -e 's,"Network": "10.244.0.0/16","Network": "192.168.0.0/16," -i kube-flannel.yml |
如果服务器有多个网卡,需要指定网卡用于flannel通信,以网卡ens33为例
- 在
args下面添加一行- --iface=ens33
1 | containers: |
修改backend
- flannel支持多种后端实现,可选值为
VXLAN、host-gw、UDP- 从性能上,
host-gw是最好的,VXLAN和UDP次之- 默认值是
VXLAN,这里以修改为host-gw为例,位置大概在75行左右
1 | net-conf.json: | |
部署kube-flannel
1 | kubectl apply -f kube-flannel.yml |
检查部署情况
1 | kubectl -n kube-system get pod -l k8s-app=flannel |
- 如果等很久都没Running,可能是quay.io对你来说太慢了
- 可以替换一下镜像,重新apply
1 | sed -e 's,quay.io/coreos/,zhangguanzhang/quay.io.coreos.,g' -i kube-flannel.yml |
Calico
说明
- Calico 是一款纯 Layer 3 的网络,节点之间基于BGP协议来通信。
- 这里以
calico-v3.4.0来作为示例- 部署文档
架构图

切换工作目录
1 | cd /root/yaml/network-plugin/calico |
下载yaml文件
- 这里使用kubernetes API来保存网络信息
1 | wget https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/hosted/kubernetes-datastore/calico-networking/1.7/calico.yaml |
- 官方yaml文件默认配置容器网络为
192.168.0.0/16,这里需要跟kube-controller-manager.conf里面的--cluster-cidr匹配,需要替换相应字段
1 | sed -e "s,192.168.0.0/16,${POD_NET_CIDR},g" -i calico.yaml |
- 官方yaml文件定义calicoctl为Pod,而不是deployment,所以需要调整一下
- 修改
kind: Pod为kind: Deployment并补充其他字段
1 | apiVersion: extensions/v1beta1 |
部署Calico
1 | kubectl apply -f /root/yaml/network-plugin/calico/ |
检查部署情况
1 | kubectl -n kube-system get pod -l k8s-app=calico-node |
- 如果镜像pull不下来,可以替换一下
- 替换完重新apply
1 | sed -e 's,quay.io/calico/,zhangguanzhang/quay.io.calico.,g' -i *yaml |
检查节点状态
- 网络组件部署完成之后,可以看到node状态已经为
Ready
1 | kubectl get node |
服务发现组件部署
- kubernetes从v1.11之后,已经使用CoreDNS取代原来的KUBE DNS作为服务发现的组件
- CoreDNS 是由 CNCF 维护的开源 DNS 方案,前身是 SkyDNS
- 在k8s-m1上操作
创建工作目录
1 | mkdir -p /root/yaml/coredns |
- 切换工作目录
1 | cd /root/yaml/coredns |
CoreDNS
创建yaml文件
1 | cat > coredns.yaml <<EOF |
修改yaml文件
- yaml文件里面定义了
clusterIP这里需要与kubelet.config.file里面定义的cluster-dns一致- 如果kubelet.conf里面的
--cluster-dns改成别的,例如x.x.x.x,这里也要做相应变动,不然Pod找不到DNS,无法正常工作- 这里定义静态的hosts解析,这样Pod可以通过hostname来访问到各节点主机
- 用下面的命令根据
HostArray的信息生成静态的hosts解析
1 | sed -e '57r '<(\ |
- 上面的命令的作用是,通过
HostArray的信息生成hosts解析配置,顺序是打乱的,可以手工调整顺序- 也可以手动修改
coredns.yaml文件来添加对应字段
1 | apiVersion: v1 |
部署CoreDNS
1 | kubectl apply -f coredns.yaml |
检查部署状态
1 | kubectl -n kube-system get pod -l k8s-app=kube-dns |
验证集群DNS服务
- 创建一个deployment测试DNS解析
1 | 创建一个基于busybox的deployment |
- 检查deployment部署情况
1 | kubectl get pod |
- 验证集群DNS解析
- 上一个命令获取到pod名字为
busybox-7b9bfb5658-872gj- 通过kubectl命令连接到Pod运行
nslookup命令测试使用域名来访问kube-apiserver和各节点主机
1 | echo "--- 通过CoreDNS访问kubernetes ---" |
Metrics Server
- Metrics Server
是实现了 Metrics API 的元件,其目标是取代 Heapster 作位 Pod 与 Node 提供资源的 Usage
metrics,该元件会从每个 Kubernetes 节点上的 Kubelet 所公开的 Summary API 中收集 Metrics- Horizontal Pod Autoscaler(HPA)控制器用于实现基于CPU使用率进行自动Pod伸缩的功能。
- HPA控制器基于Master的kube-controller-manager服务启动参数–horizontal-pod-autoscaler-sync-period定义是时长(默认30秒),周期性监控目标Pod的CPU使用率,并在满足条件时对ReplicationController或Deployment中的Pod副本数进行调整,以符合用户定义的平均Pod
CPU使用率。- 在新版本的kubernetes中 Pod CPU使用率不在来源于heapster,而是来自于metrics-server
- 官网原话是 The –horizontal-pod-autoscaler-use-rest-clients is true or unset. Setting this to false switches to Heapster-based autoscaling, which is deprecated.
- 在k8s-m1上操作
额外参数
- 设置kube-apiserver参数,这里在配置kube-apiserver阶段已经加进去了
- front-proxy证书,在证书生成阶段已经完成且已分发
1 | --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem |
创建工作目录
1 | mkdir -p /root/yaml/metrics-server |
切换工作目录
1 | cd /root/yaml/metrics-server |
下载yaml文件
1 | wget https://raw.githubusercontent.com/kubernetes-incubator/metrics-server/master/deploy/1.8%2B/aggregated-metrics-reader.yaml |
创建metrics-server-deployment.yaml
1 | cat > metrics-server-deployment.yaml <<EOF |
部署metrics-server
1 | kubectl apply -f . |
查看pod状态
1 | kubectl -n kube-system get pod -l k8s-app=metrics-server |
验证metrics
- 完成后,等待一段时间(约 30s - 1m)收集 Metrics
1 | 请求metrics api的结果 |
至此集群已具备基本功能
下面的Extra Addons就是一些额外的功能
kubernetes Extra Addons
Dashboard
- Dashboard 是kubernetes社区提供的GUI界面,用于图形化管理kubernetes集群,同时可以看到资源报表。
- 官方提供yaml文件直接部署,但是需要更改
image以便国内部署- 在k8s-m1上操作
创建工作目录
1 | mkdir -p /root/yaml/kubernetes-dashboard |
切换工作目录
1 | cd /root/yaml/kubernetes-dashboard |
获取yaml文件
1 | wget https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml |
修改镜像地址
1 | sed -e 's,k8s.gcr.io/kubernetes-dashboard-amd64,gcrxio/kubernetes-dashboard-amd64,g' -i kubernetes-dashboard.yaml |
创建kubernetes-Dashboard
1 | kubectl apply -f kubernetes-dashboard.yaml |
创建ServiceAccount RBAC
- 官方的yaml文件,ServiceAccount绑定的RBAC权限很低,很多资源无法查看
- 需要创建一个用于管理全局的ServiceAccount
1 | cat > cluster-admin.yaml <<EOF |
获取ServiceAccount的Token
1 | kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}') |
查看部署情况
1 | kubectl get all -n kube-system --selector k8s-app=kubernetes-dashboard |
访问Dashboard
- kubernetes-dashborad的svc默认是
clusterIP,需要修改为nodePort才能被外部访问- 随机分配
NodePort,分配范围由kube-apiserver的--service-node-port-range参数指定
1 | kubectl patch -n kube-system svc kubernetes-dashboard -p '{"spec":{"type":"NodePort"}}' |
- 修改完之后,通过以下命令获取访问kubernetes-Dashboard的端口
1 | kubectl -n kube-system get svc --selector k8s-app=kubernetes-dashboard |
- 可以看到已经将节点的
30216端口暴露出来
IP地址不固定,只要运行了kube-proxy组件,都会在节点上添加
30216端口规则用于转发请求到Pod登录Dashboard,上面已经获取了token,这里只需要把token的值填入输入框,点击
SIGN IN即可登录
Dashboard UI预览图
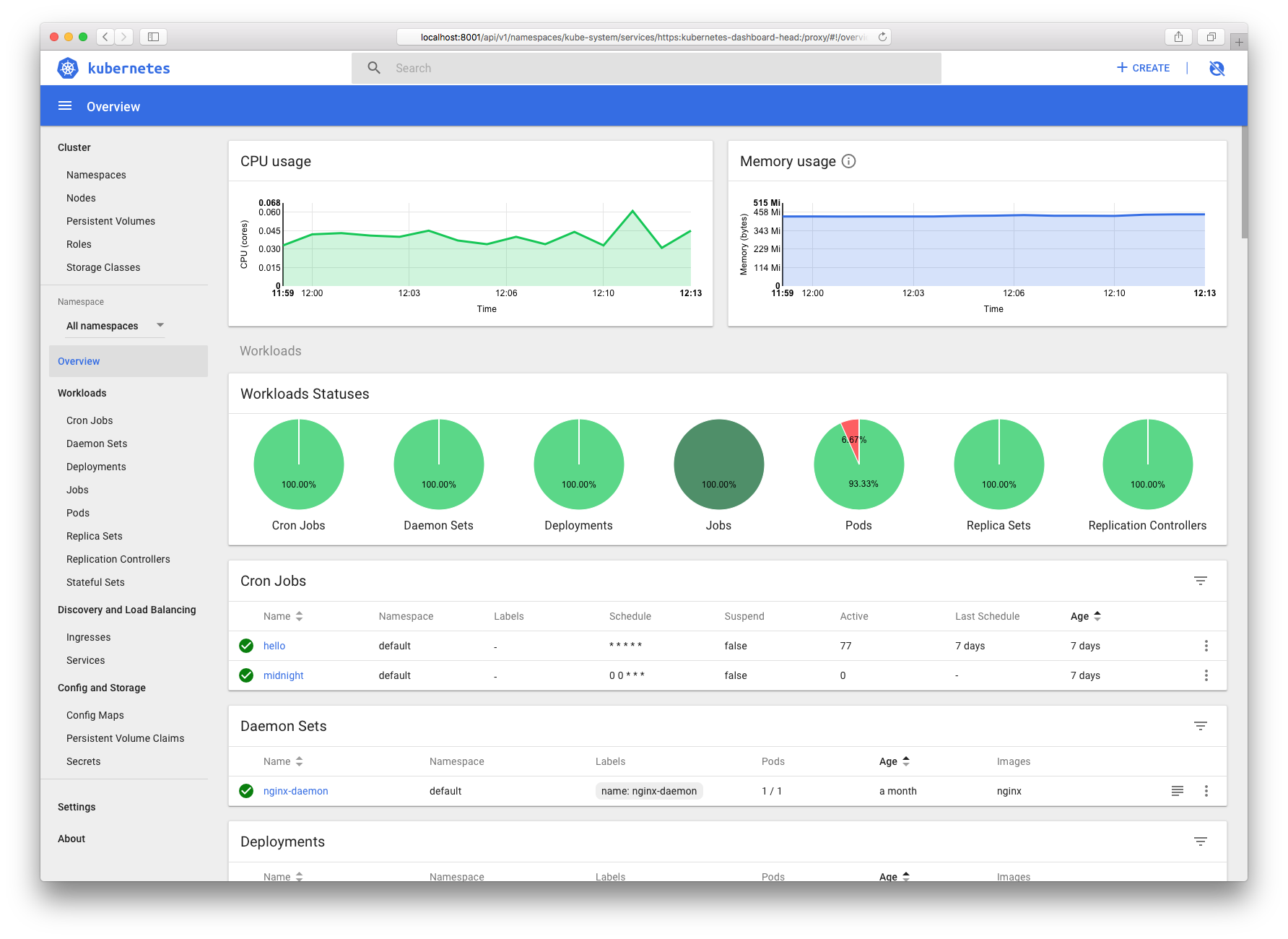
Ingress Controller
- Ingress 是 Kubernetes 中的一个抽象资源,其功能是通过 Web Server 的 Virtual Host
概念以域名(Domain Name)方式转发到內部 Service,这避免了使用 Service 中的 NodePort 与
LoadBalancer 类型所带來的限制(如 Port 数量上限),而实现 Ingress 功能则是通过 Ingress Controller
来达成,它会负责监听 Kubernetes API 中的 Ingress 与 Service 资源,并在发生资源变化时,根据资源预期的结果来设置 Web Server。- Ingress Controller 有许多实现可以选择,这里只是列举一小部分
- Ingress NGINX:Kubernetes 官方维护的方案,本次安装使用此方案
- kubernetes-ingress:由nginx社区维护的方案,使用社区版nginx和nginx-plus
- treafik:一款开源的反向代理与负载均衡工具。它最大的优点是能够与常见的微服务系统直接整合,可以实现自动化动态配置
- 在k8s-m1上操作
创建工作目录
1 | mkdir -p /root/yaml/ingress/ingress-nginx |
切换工作目录
1 | cd /root/yaml/ingress/ingress-nginx |
下载yaml文件
1 | wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.20.0/deploy/mandatory.yaml |
修改镜像地址
1 | sed -e 's,k8s.gcr.io/,zhangguanzhang/gcr.io.google_containers.,g' \ |
创建ingress-nginx
1 | kubectl apply -f . |
检查部署情况
1 | kubectl -n ingress-nginx get pod |
访问ingress
- 默认的backend会返回404
1 | kubectl -n ingress-nginx get svc |
注意
这里部署之后,是
deployment,且通过nodePort暴露服务也可以修改yaml文件,将
Ingress-nginx部署为DaemonSet
- 使用
labels和nodeSelector来指定运行ingress-nginx的节点- 使用
hostNetwork=true来共享主机网络命名空间,或者使用hostPort指定主机端口映射- 如果使用
hostNetwork共享宿主机网络栈或者hostPort映射宿主机端口,记得要看看有没有端口冲突,否则无法启动- 修改监听端口可以在
ingress-nginx启动命令中添加--http-port=8180和--https-port=8543,还有下面的端口定义也相应变更即可
创建kubernetes-Dashboard的Ingress
- kubernetes-Dashboard默认是开启了HTTPS访问的
- ingress-nginx需要以HTTPS的方式反向代理kubernetes-Dashboard
- 以HTTP方式访问kubernetes-Dashboard的时候会被重定向到HTTPS
- 需要创建HTTPS证书,用于访问ingress-nginx的HTTPS端口
创建HTTPS证书
- 这里的
CN=域名/O=域名需要跟后面的ingress主机名匹配
1 | openssl req -x509 \ |
创建secret对象
- 这里将HTTPS证书创建为kubernetes的secret对象
dashboard-tls- ingress创建的时候需要加载这个作为HTTPS证书
1 | kubectl -n kube-system create secret tls dashboard-tls --key ./tls.key --cert ./tls.crt |
创建dashboard-ingress.yaml
1 | apiVersion: extensions/v1beta1 |
创建ingress
1 | kubectl apply -f dashboard-ingress.yaml |
检查ingress
1 | kubectl -n kube-system get ingress |
访问kubernetes-Dashboard
- 修改主机hosts静态域名解析,以本文为例在hosts文件里添加
172.16.80.200 dashboard.k8s.local - 使用
https://dashboard.k8s.local:30083访问kubernetesDashboard了 - 添加了TLS之后,访问HTTP会被跳转到HTTPS端口,这里比较坑爹,没法自定义跳转HTTPS的端口
- 此处使用的是自签名证书,浏览器会提示不安全,请忽略
- 建议搭配
external-DNS和LoadBalancer一起食用,效果更佳
Helm
环境要求
- kubernetes v1.6及以上的版本,启用RBAC
- 集群可以访问到chart仓库
- helm客户端主机能访问kubernetes集群
安装客户端
安装方式二选一,需要科学上网
直接脚本安装
1 | echo '--- 使用脚本安装,默认是最新版 ---' |
下载二进制文件安装
1 | echo '--- 下载二进制文件安装 ---' |
创建工作目录
1 | mkdir /root/yaml/helm/ |
切换工作目录
1 | cd /root/yaml/helm |
创建RBAC规则
1 | cat > /root/yaml/helm/helm-rbac.yaml <<EOF |
安装服务端
- 这里指定了helm的stable repo国内镜像地址
- 具体说明请看这里
1 | helm init --tiller-image gcrxio/tiller:v2.12.0 \ |
检查安装情况
1 | kubectl -n kube-system get pod -l app=helm,name=tiller |
添加命令行补全
1 | helm completion bash > /etc/bash_completion.d/helm |
Rook(测试用途)
说明
- Rook是一款云原生环境下的开源分布式存储编排系统,目前已进入CNCF孵化。Rook的官方网站是https://rook.io
- Rook将分布式存储软件转变为自我管理,自我缩放和自我修复的存储服务。它通过自动化部署,引导、配置、供应、扩展、升级、迁移、灾难恢复、监控和资源管理来实现。 Rook使用基础的云原生容器管理、调度和编排平台提供的功能来履行其职责。
- Rook利用扩展点深入融入云原生环境,为调度、生命周期管理、资源管理、安全性、监控和用户体验提供无缝体验。
- Ceph Custom Resource Definition(CRD)已经在Rook v0.8版本升级到Beta
- 其他特性请查看项目文档
- 这里只用作测试环境中提供StorageClass和持久化存储
- 请慎重考虑是否部署在生产环境中
Rook与kubernetes的集成
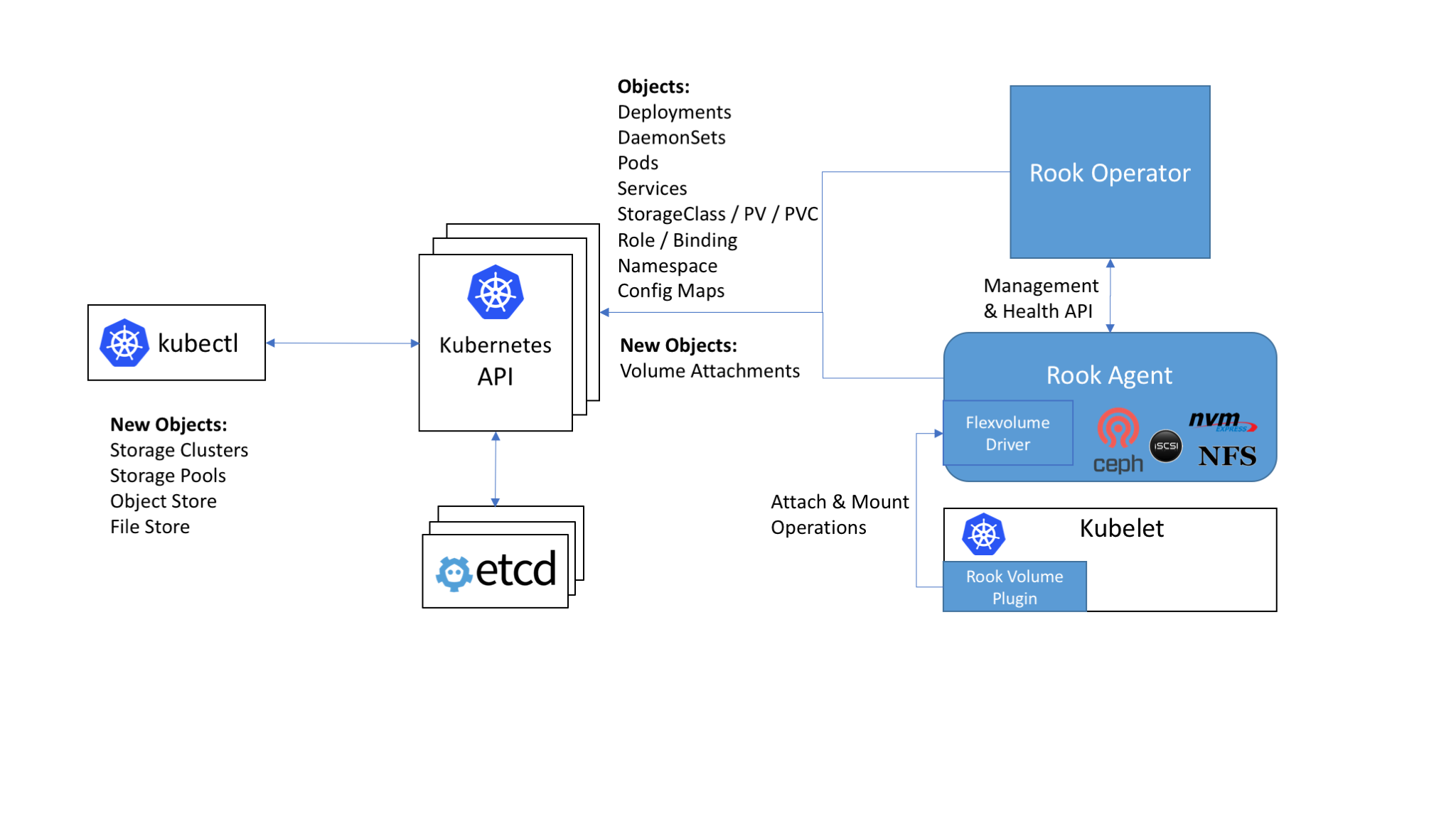
Rook架构图
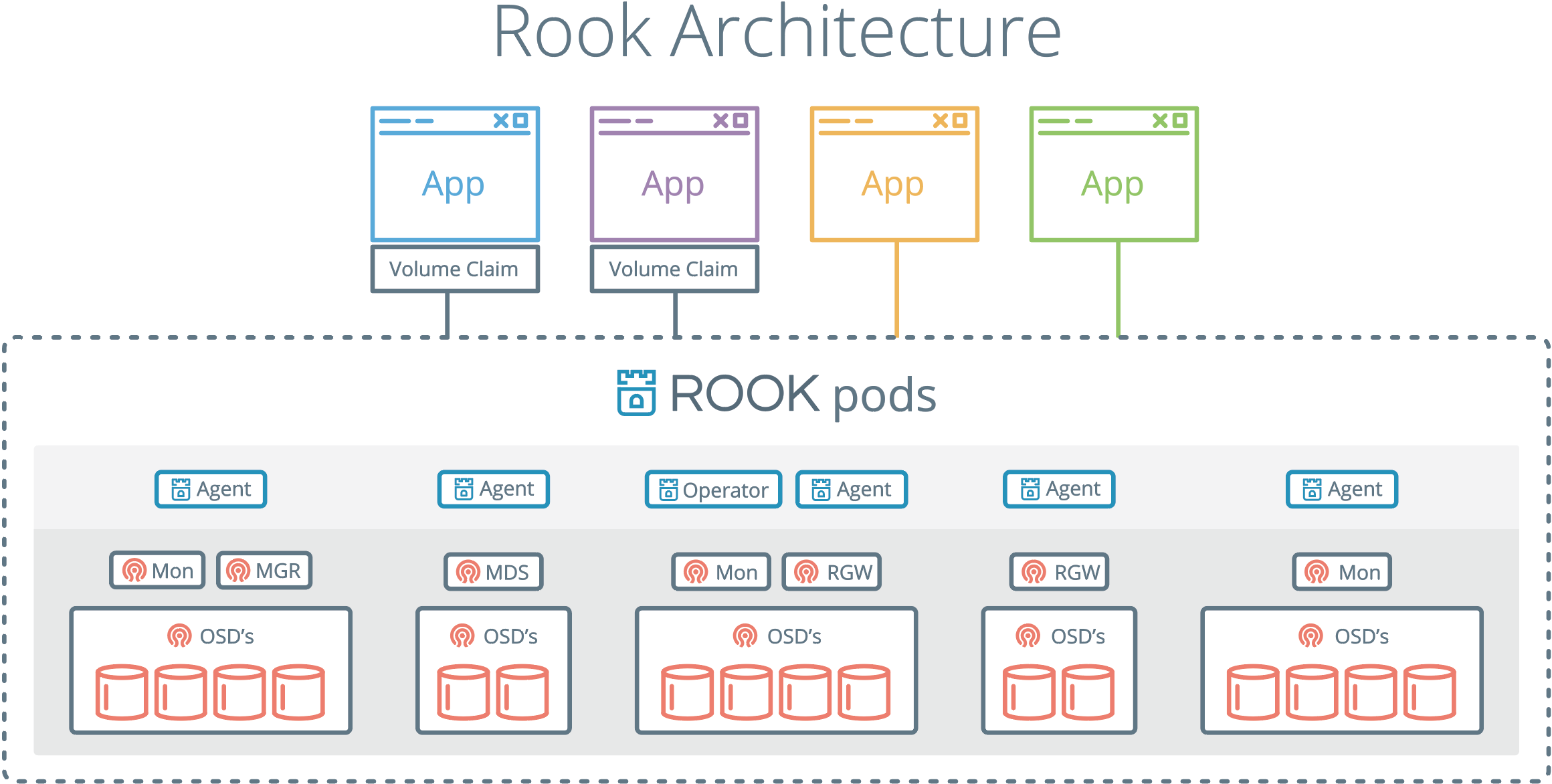
安装
- 这里以
Rook v0.8.3作为示例 - 这里默认使用
/var/lib/rook/osd*目录来运行OSD - 需要最少3个节点,否则无足够的节点启动集群
- 可以使用
yaml文件部署和使用helm chart部署,这里使用yaml文件部署
创建工作目录
1 | mkdir -p /root/yaml/rook/ |
进入工作目录
1 | cd /root/yaml/rook/ |
下载yaml文件
1 | operator实现自定义API用于管理rook-ceph |
部署operator
1 | kubectl apply -f operator.yaml |
检查operator安装情况
1 | kubectl -n rook-ceph-system get all |
部署cluster
1 | kubectl apply -f cluster.yaml |
检查cluster部署情况
1 | kubectl -n rook-ceph get all |
检查ceph集群状态
- 上面命令已经获取ceph-mon0节点的pod名
rook-ceph-mon0-ll7fc,以此pod为例运行以下命令
1 | kubectl -n rook-ceph exec -it rook-ceph-mon0-ll7fc -- ceph -s |
暴露ceph-mgr的dashboard
1 | wget https://raw.githubusercontent.com/rook/rook/v0.8.3/cluster/examples/kubernetes/ceph/dashboard-external.yaml |
访问已暴露的dashboard
1 | kubectl -n rook-ceph get svc |
- 可以见到这里暴露
30660端口,通过此端口可以访问Dashboard
添加StorageClass
- 添加
多副本存储池- 注释部分是创建
纠删码存储池- 添加
StorageClass指定使用多副本存储池,格式化为xfs
1 | cat > rbd-storageclass.yaml <<EOF |
- 还可以添加
cephFS和object类型的存储池,然后创建对应的StorageClass
具体可以看filesystem.yaml和object.yaml
检查StorageClass
- 创建sc时,会在
rook-ceph上创建对应的Pool- 这里以
rbd-storageclass.yaml为例
1 | kubectl get sc |
卸载Rook-ceph
- 这里提供卸载的操作步骤,请按需操作!
删除StorageClass
1 | kubectl delete -f rbd-storageclass.yaml |
删除Rook-Ceph-Cluster
1 | kubectl delete -f cluster.yaml |
删除Rook-Operator
1 | kubectl delete -f operator.yaml |
清理目录
- 注意!这里是所有运行rook-ceph集群的节点都需要做清理
1 | rm -rf /var/lib/rook |
Prometheus Operator
说明
- Prometheus Operator 是 CoreOS 开发的基于 Prometheus 的 Kubernetes 监控方案,也可能是目前功能最全面的开源方案。
- Prometheus Operator 通过 Grafana 展示监控数据,预定义了一系列的 Dashboard
- 要求kubernetes版本大于等于
1.8.0- CoreOS/Prometheus-Operator项目地址
Prometheus
- Prometheus 是一套开源的系统监控报警框架,启发于 Google 的 borgmon 监控系统,作为社区开源项目进行开发,并成为CNCF第二个毕业的项目(第一个是kubernetes)
- 特点
- 强大的多维度数据模型
- 灵活而强大的查询语句(PromQL)
- 易于管理,高效
- 使用 pull 模式采集时间序列数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的 metrics。
- 可以采用 push gateway 的方式把时间序列数据推送至 Prometheus server 端
- 可以通过服务发现或者静态配置去获取监控的 targets
- 有多种可视化图形界面
- 易于伸缩
Prometheus组成架构
- Prometheus Server: 用于收集和存储时间序列数据
- Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给
Prometheus server- Push Gateway: 主要用于短期的 jobs。 jobs 可以直接向 Prometheus server 端推送它们的
metrics。这种方式主要用于服务层面的 metrics。- Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
- Alertmanager: 从 Prometheus server 端接收到 alerts
后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。
架构图

Operator架构
Operator
即 Prometheus Operator,在 Kubernetes 中以 Deployment 运行。其职责是部署和管理
Prometheus Server,根据 ServiceMonitor 动态更新 Prometheus Server 的监控对象。Prometheus Server
Prometheus Server 会作为 Kubernetes 应用部署到集群中。为了更好地在 Kubernetes 中管理 Prometheus,CoreOS 的开发人员专门定义了一个命名为
Prometheus类型的 Kubernetes 定制化资源。我们可以把Prometheus看作是一种特殊的 Deployment,它的用途就是专门部署 Prometheus Server。Service
这里的
Service 就是 Cluster 中的 Service 资源,也是 Prometheus 要监控的对象,在 Prometheus 中叫做
Target。每个监控对象都有一个对应的 Service。比如要监控 Kubernetes Scheduler,就得有一个与 Scheduler
对应的 Service。当然,Kubernetes 集群默认是没有这个 Service 的,Prometheus Operator
会负责创建。ServiceMonitor
Operator
能够动态更新 Prometheus 的 Target 列表,ServiceMonitor 就是 Target 的抽象。比如想监控
Kubernetes Scheduler,用户可以创建一个与 Scheduler Service 相映射的 ServiceMonitor
对象。Operator 则会发现这个新的 ServiceMonitor,并将 Scheduler 的 Target 添加到 Prometheus
的监控列表中。ServiceMonitor 也是 Prometheus Operator 专门开发的一种 Kubernetes 定制化资源类型。
Alertmanager
除了 Prometheus 和 ServiceMonitor,Alertmanager 是 Operator 开发的第三种 Kubernetes 定制化资源。我们可以把
Alertmanager看作是一种特殊的 Deployment,它的用途就是专门部署 Alertmanager 组件。

部署Prometheus-Operator
切换工作目录
1 | mkdir -p /root/yaml/prometheus-operator |
添加coreos源
1 | 添加coreos源 |
创建命名空间
1 | kubectl create namespace monitoring |
部署prometheus-operator
- 这里通过
--set指定了image的地址
1 | helm install coreos/prometheus-operator \ |
部署kube-prometheus
- 通过运行
helm命令安装时,指定一些变量来达到自定义配置的目的- 定义
grafana初始admin密码为password,默认值是admin- 定义
alertmanager和prometheus使用名为rook-ceph-block的StorageClass,访问模式为ReadWriteOnce,大小5Gi,默认是50Gi- 定义
grafana、alertmanager、prometheus的Service类型为NodePort,默认是ClusterIP- 这里的
--set可以定义很多变量,具体可以在这里,查看里面每个文件夹的values.yaml- 这里配置的变量请自己根据情况修改
1 | helm install coreos/kube-prometheus \ |
检查部署情况
1 | kubectl -n monitoring get all |
访问Prometheus-Operator
- 部署时已经定义alertmanager、prometheus、grafana的Service为NodePort
- 根据检查部署的情况,得知
kube-prometheus的NodePort为30900kube-prometheus-alertmanager的NodePort为30903kube-prometheus-grafana的NodePort为30164- 直接通过这些端口访问即可
- grafana已内嵌了基础的Dashboard模板,以
admin用户登录即可见
EFK
说明
- 官方提供简单的
fluentd-elasticsearch样例,可以作为测试用途- 已经包含在
kubernetes项目当中链接- 这里使用
kubernetes-server-linux-amd64.tar.gz里面的kubernetes-src.tar.gz提供的Addons- 修改
elasticsearch使用rook-ceph提供的StorageClass作为持久化存储,默认是使用emptyDir
注意
- EFK集群部署之后,
kibana和elasticsearch初始化过程会极大的消耗服务器资源- 请保证你的环境能撑的住!!!!
- 配置不够,服务器真的会失去响应
- 实测3节点4C 16G SSD硬盘,CPU持续十几分钟的满载
解压源代码
1 | tar xzf kubernetes-server-linux-amd64.tar.gz kubernetes/kubernetes-src.tar.gz |
切换工作目录
1 | cd cluster/addons/fluentd-elasticsearch/ |
修改yaml文件
- 删除es-statefuleset.yaml里面的字段,位置大概在100行左右
1 | volumes: |
- 添加
volumeClaimTemplates字段,声明使用rook-ceph提供的StorageClass,大小5Gi- 位置在
StatefulSet.spec,大概67行左右
1 | volumeClaimTemplates: |
- 修改后,
es-statefulset.yaml内容如下
1 | # RBAC authn and authz |
- 注释
kibana-deployment.yaml定义的环境变量- 大概在35行左右
1 | - name: SERVER_BASEPATH |
修改镜像地址
- 默认yaml定义的镜像地址是
k8s.gcr.io,需要科学上网- 变更成
gcrxio
1 | sed -e 's,k8s.gcr.io,gcrxio,g' -i *yaml |
给节点打Label
fluentd-es-ds.yaml有nodeSelector字段定义了运行在带有beta.kubernetes.io/fluentd-ds-ready: "true"标签的节点上- 这里为了方便,直接给所有节点都打上标签
1 | kubectl label node --all beta.kubernetes.io/fluentd-ds-ready=true |
部署EFK
1 | kubectl apply -f . |
查看部署情况
1 | kubectl -n kube-system get pod -l k8s-app=elasticsearch-logging |
访问EFK
- 修改
elasticsearch和kibana的svc为nodePort
1 | kubectl patch -n kube-system svc elasticsearch-logging -p '{"spec":{"type":"NodePort"}}' |
- 查看分配的
nodePort
1 | kubectl -n kube-system get svc -l k8s-app=elasticsearch-logging |
- 可以看到端口分别为
30542和30998
在github上获取yaml文件
- 如果不想用
kubernetes-src.tar.gz里面的Addons- 可以直接下载github上面的文件,也是一样的
1 | wget https://raw.githubusercontent.com/kubernetes/kubernetes/${KUBERNETES_VERSION}/cluster/addons/fluentd-elasticsearch/es-service.yaml |